TL;DR
- We trained our 3D pose estimator on lots of datasets.
- It works very well (see video).
- You can try it live at ECCV'22 in Tel Aviv, on Wednesday.
- You can run it yourself, for non-commercial research.
Show me the Code!
# 'pip install tensorflow tensorflow-hub' if not yet installed
import tensorflow as tf
import tensorflow_hub as hub
model = hub.load('https://bit.ly/metrabs_l') # or _s
image = tf.image.decode_image(tf.io.read_file('test.jpg')) # image can have any size
preds = model.detect_poses(image, skeleton='smpl+head_30')
preds['boxes'] # shape: [num_people, 5], the 5 are [x_left, y_top, width, height, confidence]
preds['poses3d'] # shape: [num_people, 30, 3], in millimeters
preds['poses2d'] # shape: [num_people, 30, 2], in pixelsDescription
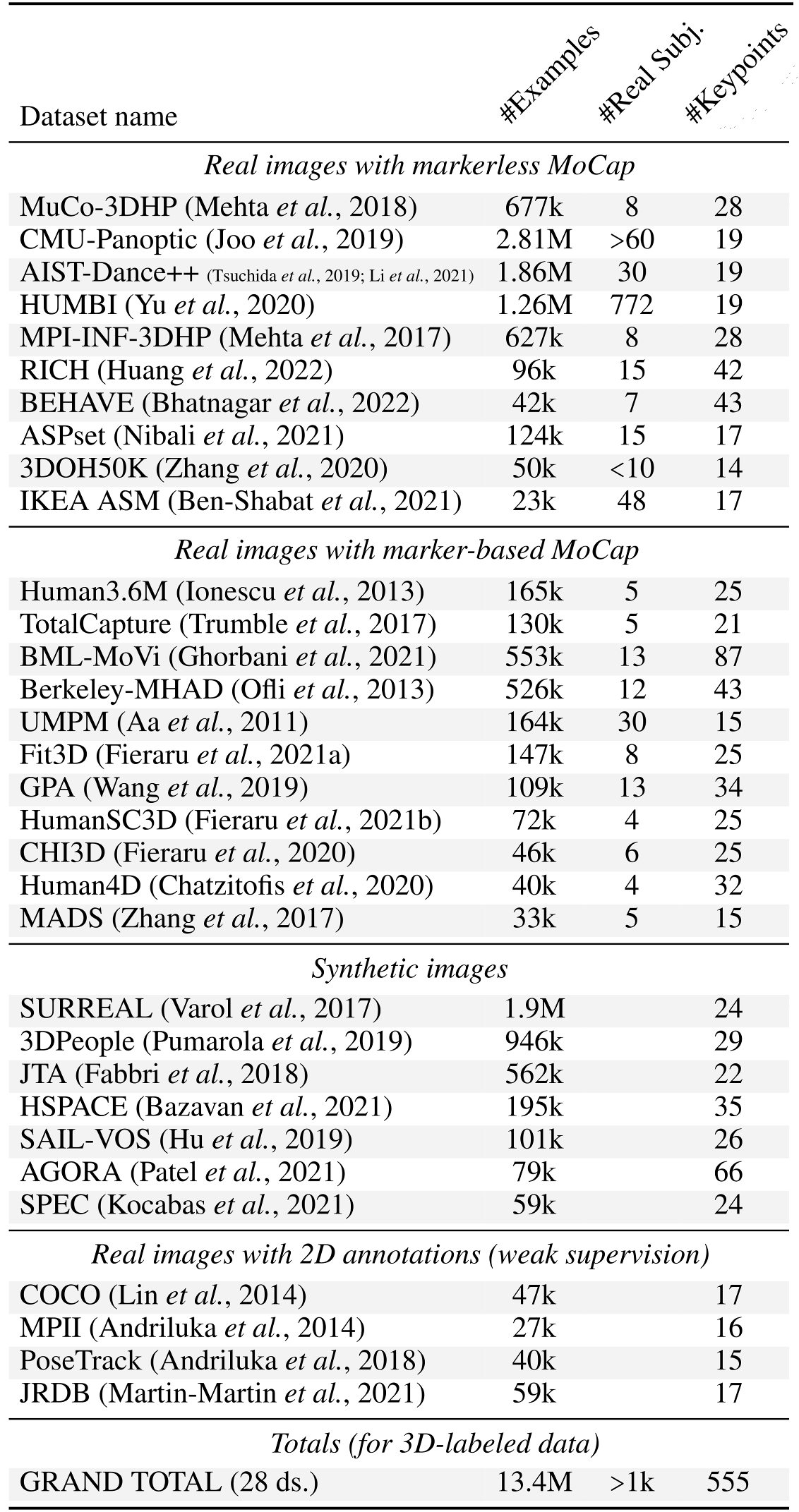
We show a real-time-capable method for high-quality monocular single-frame 3D human pose estimation, running on a laptop. Our simple and efficient models are the culmination of a large-scale dataset merging effort, where we collected and preprocessed over 13 million images labeled with 3D human poses, from 28 individual pre-existing datasets, which is the largest such undertaking we are aware of. Mainly due to this scale of data, the resulting models are highly accurate and top several benchmarks (with a large model achieving 57.0 mm MPJPE on 3DPW, 97.6% PCK on MPI-INF-3DHP, 35.5 mm MPJPE on Human3.6M).
The approach is based on our prior work MeTRAbs (repo), which won the 3DPW Challenge at the previous ECCV (2020). Besides using much more training data, we also developed a novel way to deal with different skeleton annotation formats across different datasets. The corresponding paper has been accepted at WACV 2023 and will be made available soon.
In the demo, we use a single webcam to capture an input video feed of multiple people. The frames are processed independently by our pose estimator and the resulting absolute 3D human poses are visualized on a TV screen. Our goal with the demo is to let people interact with the system, see its high quality, and consider applying it in their own research when they need a simple off-the-shelf 3D human pose estimator.
We release model files packaged for ease of use, without requiring complex dependencies, thus bringing high quality off-the-shelf 3D human pose estimation to a broad range of researchers, enabling exciting downstream research applications.
Panoptic Dataset Results
To inspect the prediction quality along the depth axis, we visualize results on a challenging CMU-Panoptic dance sequence. Note that our prediction (blue-yellow skeleton) is monocular. The currently active camera is highlighted in the visualization with a thick blue frame. The red skeleton is the result of triangulation.
We have two visualizations for Panoptic. In the first case we adjust the scale/distance of the prediction such that the pelvis depth aligns with the triangulated pelvis depth. (This does not evaluate the absolute 3D pose, i.e. the location prediction)
The second visualization shows the raw prediction, without scale/distance alignment:
JackRabbot Dataset Results
Predictions on a JackRabbot (JRDB) test sequence. (Double predictions occur when a person is seen from two cameras. These could be removed with cross-view non-maximum suppression.)