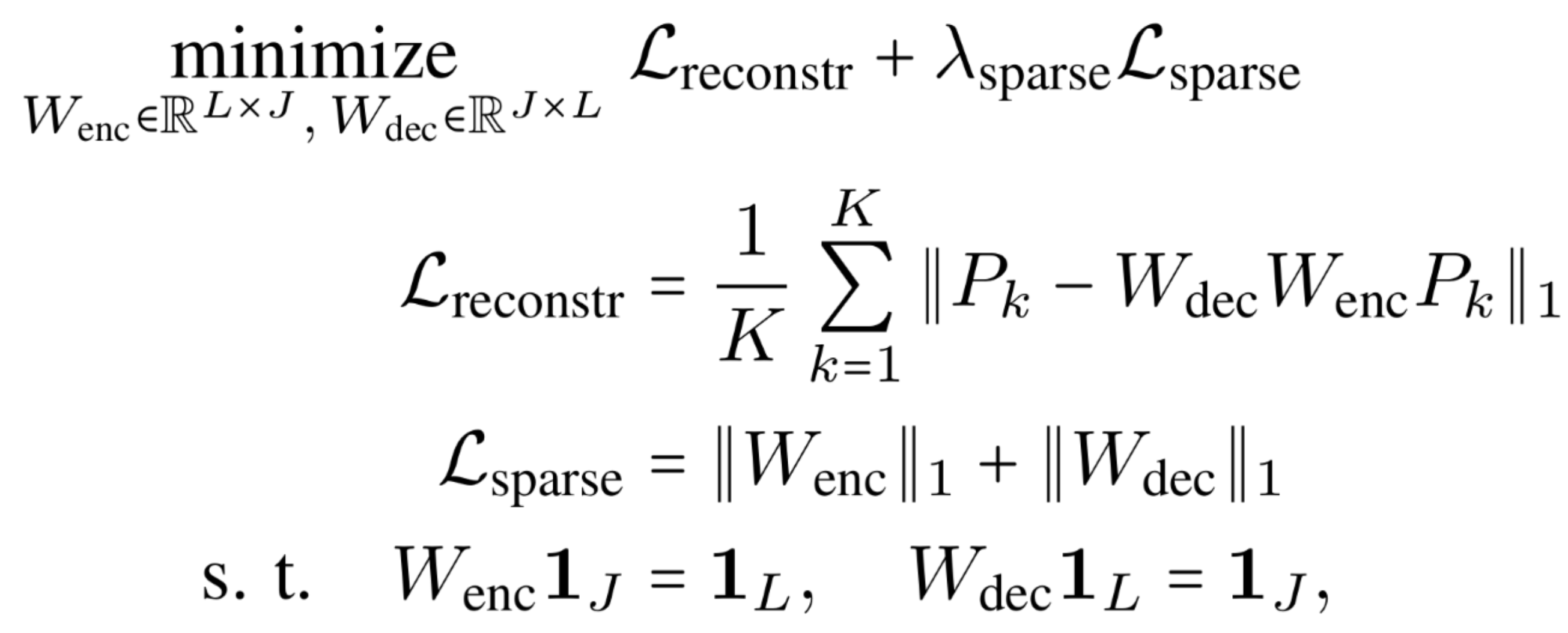
To enable accurate 3D human pose estimation in downstream research applications, we aim to train on every labeled dataset we can get our hands on. However, different datasets use incompatible skeleton formats. We discover how these skeletons are related using our novel affine-combining autoencoder, enabling extreme multi-dataset training on 28 datasets, and thus very strong models.
Some examples for the different formats:
Further qualitative videos here.
We use a 3-step workflow:
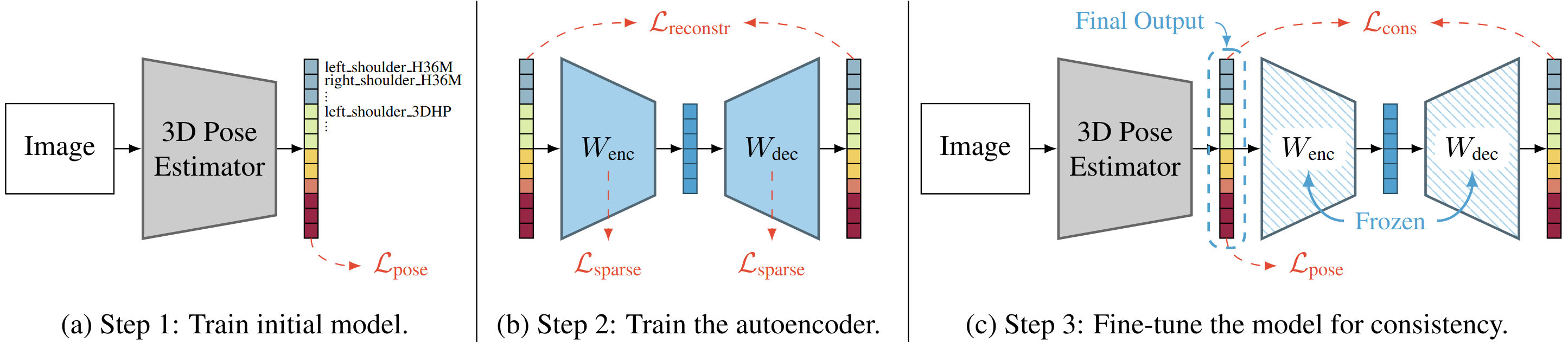
One of our contributions is a simple linear autoencoder formulation, where both the encoder and the decoder compute affine combinations of its input points. This ensures equivariance to rotation and translation (see paper for chirality equivariance). Crucially, it also allows knowledge transfer of skeleton relations from the 2D to the depth axis (2D is more accurate in the pseudo-GT). Furthermore, the information bottleneck of this autoencoder is a list of geometrically interpretable latent 3D keypoints that can also be directly predicted and can serve as an interface between different skeleton formats.
In the paper we first show that scaling up the data indeed helps. Then we show that the skeleton consistency improves with our proposed consistency regularization.
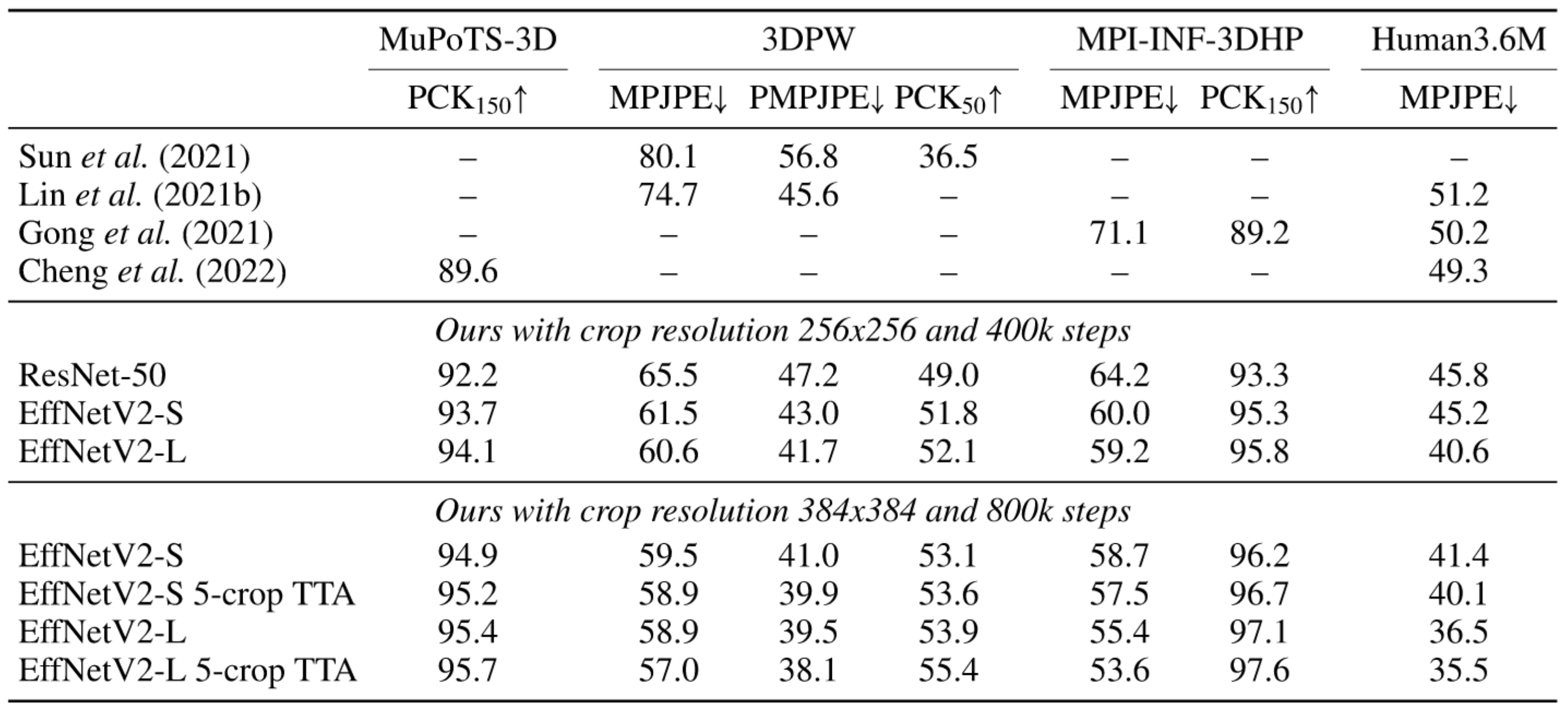
But what's even more important from the application point of view is that the final models are MUCH stronger than currently available models that are trained on less data:
# 'pip install tensorflow tensorflow-hub' if not yet installed
import tensorflow as tf
import tensorflow_hub as hub
model = hub.load('https://bit.ly/metrabs_l') # or _s
image = tf.image.decode_image(tf.io.read_file('test.jpg')) # image can have any size
preds = model.detect_poses(image, skeleton='smpl+head_30')
preds['boxes'] # shape: [num_people, 5], the 5 are [x_left, y_top, width, height, confidence]
preds['poses3d'] # shape: [num_people, 30, 3], in millimeters
preds['poses2d'] # shape: [num_people, 30, 2], in pixelsMore options in the API docs.
Models: The following models are available according to backbone and crop resolution, all using YOLOv4 as a built-in detector:
hub.load('https://bit.ly/metrabs_s_256')hub.load('https://bit.ly/metrabs_s')hub.load('https://bit.ly/metrabs_l')hub.load('https://bit.ly/metrabs_xl')
Skeletons: The following skeleton formats are supported in all of the above models (the suffix stands for the number of keypoints):
smpl_24, kinectv2_25, h36m_17, h36m_25, mpi_inf_3dhp_17, mpi_inf_3dhp_28, coco_19, smplx_42, ghum_35, lsp_14, sailvos_26, gpa_34, aspset_17, bml_movi_87,
mads_19, berkeley_mhad_43, total_capture_21, jta_22, ikea_asm_17, human4d_32, 3dpeople_29, umpm_15, smpl+head_30.
Real-time capability: The EffNetV2-S model runs at 28 FPS without batching on the RTX 3090 consumer GPU, when processing the multiperson MuPoTS-3D dataset.
Code for dataset preprocessing and training the ACAE is coming soon!
Deep learning-based 3D human pose estimation performs best when trained on large amounts of labeled data, making combined learning from many datasets an important research direction. One obstacle to this endeavor are the different skeleton formats provided by different datasets, i.e., they do not label the same set of anatomical landmarks. There is little prior research on how to best supervise one model with such discrepant labels. We show that simply using separate output heads for different skeletons results in inconsistent depth estimates and insufficient information sharing across skeletons. As a remedy, we propose a novel affine-combining autoencoder (ACAE) method to perform dimensionality reduction on the number of landmarks. The discovered latent 3D points capture the redundancy among skeletons, enabling enhanced information sharing when used for consistency regularization. Our approach scales to an extreme multi-dataset regime, where we use 28 3D human pose datasets to supervise one model, which outperforms prior work on a range of benchmarks, including the challenging 3D Poses in the Wild (3DPW) dataset. Our code and models are available for research purposes.
@inproceedings{Sarandi2023dozens,
author = {S\'ar\'andi, Istv\'an and Hermans, Alexander and Leibe, Bastian},
title = {Learning {3D} Human Pose Estimation from Dozens of Datasets using a Geometry-Aware Autoencoder to Bridge Between Skeleton Formats},
booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2023}
}
As the base pose estimator model, we use our earlier MeTRAbs in this work:
@article{Sarandi2021metrabs,
title = {{MeTRAbs:} Metric-Scale Truncation-Robust Heatmaps for Absolute {3D} Human Pose Estimation},
author = {S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
journal = {IEEE Transactions on Biometrics, Behavior, and Identity Science (T-BIOM)},
volume = {3},
number = {1},
pages = {16--30},
year = {2021}
}